
在上一篇中提到, post 方式按 enctype 的不同, 分成两种情况, 一种是 application/x-www-form-urlencoded, 前面已经分析过了, 这一篇则讨论剩下的那种: multipart/form-data.
为什么需要 multipart/form-data 类型?
虽然在很多的情况下, 都可以使用缺省的 application/x-www-form-urlencoded 方式, 但它是有缺点的, 比如它编码的效率不高, 因为它采用了低效的转义表示法.
举个例子来说, "你好" 两字用 gbk 编码只需要 4 个字节: C4 E3 BA C3. 如下:
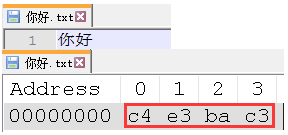
而如果表示成转义的形式呢? 是这样的 %C4%E3%BA%C3, 这一串整整有 12 个 ASCII 字符, 一个 ASCII 字符就要用一个字节来表示, 所以转义形式需要 12 字节, 是非转义形式的三倍:

可以看到光是百分号(%, ASCII 为 0x25)本身就占了 4 个字节了.
另外的情况是, 有时表单上还有上传文件的需求, 这时候 HTML 规范要求只能使用 multipart/form-data 形式.
post 方式以 multipart/form-data 类型提交的一个示例
和之前类似, 通过具体的示例来探究 multipart 时的编码. 先构建一个这样的表单:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>form post multipart</title>
</head>
<body>
<h2>post 提交, 页面编码: UTF-8;enctype: multipart/form-data</h2><hr>
<form action="/jcc-web/encoding/form/post/upload" method="post" enctype="multipart/form-data">
<input name="english" value="hi">
<input name="chinese" value="你好">
<input name="f1" type="file">
<input type="submit" value="submit">
</form>
</body>
</html>
页面本身编码为 utf-8, 表单 method 为 post, enctype 为 multipart/form-data, 表单中含有一个类型为 file 的 input 项用作为文件上传, 提交到后台的一个叫 upload 的 servlet 上.
准备的上传文件就是上面提到的那个, 名为 "你好.txt", 文件内容就是两个简单的汉字"你好", 文件本身用 gbk 编码.
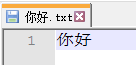
所以文件本身大小为 4 字节, 字节内容具体为: C4 E3 BA C3.
以 multipart/form-data 类型提交时的编码
将以上程序部署并在浏览器打开, 选中要上传的文件 "你好.txt", 准备提交:
在提交之前, 打开"开发者工具", 然后点击提交以截获其具体的请求, 在 header 中的 Request Payload 下可以看到提交的具体情况:
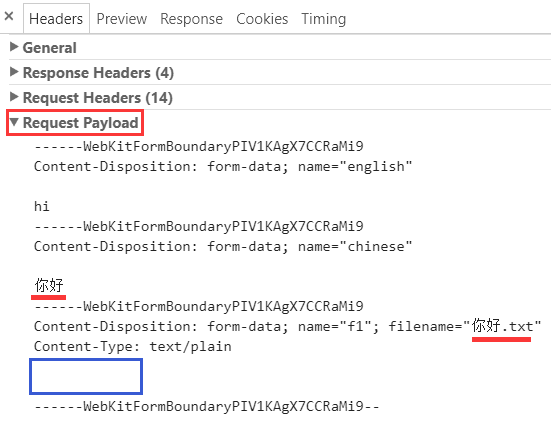
从中能够发现一些细节, 比如中文没有进行转义的 urlencoded(不过因此也看不出来它到底是采用何种字符集编码, 因为直接显示为字符);另外这里只显示了文件名, 文件本身的内容它没有显示出来(文中蓝色框部分).
当然可以通过前面提到的 Fiddler 工具来截获请求的内容:
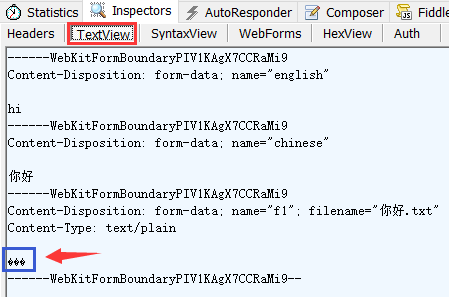
在 TextView 下可以看到结果是类似的, 文件内容还能看到三个乱码字符. 转到 HexView 查看十六进制数据:
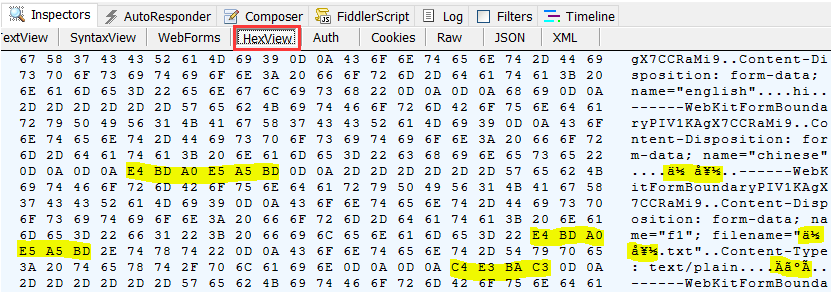
找到中文出现的几处关键地方(图中用黄色高亮标注), 不难发现:
- 表单中的普通中文 input 项 "chinese"(具体值为"你好")的编码为: E4 BD A0 E5 A5 BD, 编码很显然为 utf-8, 并且是原生的形式, 没有转义.
- 表单中上传"文件名"(具体值为"你好.txt")的中文部分的编码为: E4 BD A0 E5 A5 BD, 编码同样为 utf-8, 并且是原生的形式, 没有转义.
- 表单中上传文件的"文件内容"部分(具体值同样为"你好")的编码为: C4 E3 BA C3. 就是文件本身的字节序列. (具体编码为 gbk)
通过以上观察不难得出一个初步的结论:
- multipart 形式的上传使用原生的编码, 而这一编码的来源不难猜到就是页面文档本身的编码.
- 上传的文件的内容则忠实于文件本身. 文件内容的上传本身仅是一个字节流的拷贝过程而已, 不会涉及到字符集编码.
很多时候上传的"文件内容"根本就不是文本文件, 比如很多时候会上传的图片文件, 因此这一过程是跟字符集编码无关的, 跟字符集编码有关的仅仅是"文件名"部分.
后端接收 multipart 时的处理
说完了提交的部分, 再看后台接收处理的方面, 具体用一个 servlet 来处理, 对于 multipart 形式的提交, 需要引入一个注解 @MultipartConfig, 这样 request.getParameter 才能取到值:
package org.jcc.servlet.encoding.form.post;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.MultipartConfig;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.Part;
@WebServlet("/encoding/form/post/upload")
@MultipartConfig
public class Upload extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
String english = request.getParameter("english");
String chinese = request.getParameter("chinese");
Part f1part = request.getPart("f1");
String fileName = f1part.getSubmittedFileName();
InputStream is = f1part.getInputStream();
InputStreamReader reader = new InputStreamReader(is, "gbk");
// output to client
response.setContentType("text/html;charset=utf-8");
PrintWriter writer = response.getWriter();
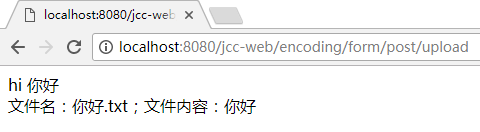
writer.print(english + " " + chinese + "<br>");
writer.print("文件名: " + fileName + ";文件内容: ");
int c;
while((c = reader.read()) != -1) {
writer.write((char) c);
}
}
}
有两点要注意的:
request.setCharacterEncoding("utf-8"), 跟之前是一样的, 如果不设置, servlet 缺省按 iso-8859-1 去解码, 将导致乱码.注: 不过对于
part.getSubmittedFileName获取上传文件名而言, 虽然它也受到setCharacterEncoding方法的影响, 但它的缺省是 utf-8 而不是 iso-8859-1, 至少我本地实验时发现它是如此的.getSubmittedFileName方法在 servlet 3.1 标准后引入的.- 获得上传"文件内容"本身使用
getPart方法, 会返回一个Part接口的实现, 可以通过其getInputStream获得上传的字节流. 然后构建reader时传入的编码为 gbk, 因为它是这段字节流真正的编码.
如果以上设置均 OK, 结果页面将是正常的:
使用 accept-charset 属性时的编码
与前面类似, 使用 multipart 时表单同样可以使用 accept-charset 指定一个编码, 可以与页面文档本身的编码不同, 而且表单此时也优先采纳 accept-charset 指定的值. 比如下面就改变了前面的表单:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>form post multipart</title>
</head>
<body>
<h2>post 提交, 页面编码: UTF-8;enctype: multipart/form-data</h2><hr>
<form action="/jcc-web/encoding/form/post/upload" method="post"
enctype="multipart/form-data"
accept-charset="gbk">
<input name="english" value="hi">
<input name="chinese" value="你好">
<input name="f1" type="file">
<input type="submit" value="submit">
</form>
</body>
</html>
这样之后, 提交的数据将采用 gbk 编码而不是文档本身的 utf-8:
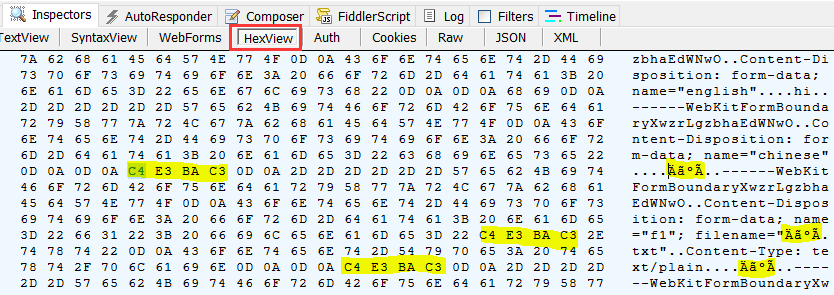
可以看到, 高亮的前两处地方编码都是 gbk 了.
当然, 最后的"文件内容"本身该怎样还是怎样, 不受这里调整影响. (因它本身就是 gbk, 所以这里三处的值都一样了)
相应的, 后台部分的 request.setCharacterEncoding 也要调整, 否则中文字段与中文文件名都将出现乱码:
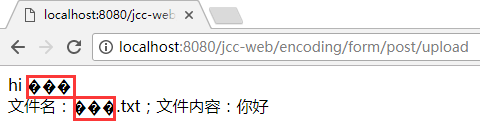
注: "文件内容"本身是独立的, 将不受这里的影响, 只与
new InputStreamReader时传入的编码参数有关, 所以这里显示还是 OK 的.关于这方面, 可以参考前面的 Java 字节流与字符流系列中的介绍.
调整为 setCharacterEncoding("gbk") 后结果将显示正常, 具体截图从略, 读者可自行实验.
总之, 后台解码要与前台编码的一致即可. 当发生乱码时, 首先要检查前台提交过来的数据, 确定它使用的真实编码, 可以通过浏览器的"开发者工具"或者一些抓包工具(比如这里提到的 Fiddler, 其它的还有比如 wiresharp 之类的), 之后, 在后台作相应更改.
如果你用的不是 Java servlet 平台, 或者 server 用的不是 tomcat 之类的, 某些具体的处理过程可能会有差异, 但基本上可以说是大同小异, 因为从根本上讲, 都是对 html, http, uri 等规范的实现, 这些统一的规范适用于所有的语言与平台.
总结
下面对 multipart 形式的提交做个总结, 其实总的来说, 跟前面的那些 get 方式以及 urlencoded 的 post 方式是差不多的:
- 没有用 accept-charset 指定, 就用文档本身的编码, 但不会转义;
- 设置了 accept-charset 的值, 就用它设置的值, 但不会转义;
- "文件名" 跟表单字段使用相同的编码, 同样也不会转义;
- "文件内容" 本身按其原样字节上传, 不涉及编码问题.
可以说, 不管是 get, 还是 urlencoded 的 post, 还是这里 multipart 的 post, 基本逻辑都是差不多的.
示例代码(git)与参考
前面很多的示例代码基本都是用图片的方式给出的, 如果你想拷贝一些代码亲自实验, 可以到我的 gitee 共享工程下看到这些示例代码: https://gitee.com/goldenshaw/java_code_complete/tree/master/jcc-web/src/main/webapp/demo/encoding/form/post
另外, 写作的过程中主要参考是:
- https://www.w3.org/TR/html401/interact/forms.html
- https://docs.oracle.com/javaee/6/tutorial/doc/glrbb.html
关于 post 方式以 multipart/form-data 类型提交的介绍就到这里, 关于整个表单提交时的编码与乱码的主题也介绍完了.