在上一篇中提到, post 方式按 enctype 的不同, 分成两种情况, 一种是 application/x-www-form-urlencoded, 前面已经分析过了, 这一篇则讨论剩下的那种: multipart/form-data.
为什么需要 multipart/form-data 类型?
虽然在很多的情况下, 都可以使用缺省的 application/x-www-form-urlencoded 方式, 但它是有缺点的, 比如它编码的效率不高, 因为它采用了低效的转义表示法.
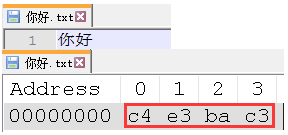
举个例子来说, "你好" 两字用 gbk 编码只需要 4 个字节: C4 E3 BA C3. 如下:
而如果表示成转义的形式呢? 是这样的 %C4%E3%BA%C3, 这一串整整有 12 个 ASCII 字符, 一个 ASCII 字符就要用一个字节来表示, 所以转义形式需要 12 字节, 是非转义形式的三倍:

可以看到光是百分号(%, ASCII 为 0x25)本身就占了 4 个字节了.
另外的情况是, 有时表单上还有上传文件的需求, 这时候 HTML 规范要求只能使用 multipart/form-data 形式.