
在上一篇中介绍了字节流与字符流的关系, 这一篇主要给出一些具体的代码示例.
使用字节流读取文本文件
上篇中说到, 无论是字符流还是字节流, 都可以用于读取文本文件, 特别是对于一整个文件的读取, 两者的差别并不大. 来看一个具体的示例, 假如有如下 gbk 编码的 txt 文件一枚, 具体内容为"hi你好", 对应二进制如下:

那么可以这样去读取:
import static org.assertj.core.api.Assertions.assertThat;
import java.nio.file.Files;
import java.nio.file.Paths;
import org.junit.Test;
@Test
public void testReadByByte() throws Exception {
byte[] bytes = Files.readAllBytes(
Paths.get(getClass().getResource("/encoding/gbk_demo.txt").toURI()));
String s = new String(bytes, "gbk");
assertThat(s).isEqualTo("hi你好");
}
也就是先原封不动地把对于字节拷贝到内存中, 再通过 new String 即可构建出相应的字符串.
注意
new String时传入的编码是 gbk.
使用字符流读取文本文件
对于同样的这个文件, 现在采用字符流的方式. 那么首先是构建相应编码(也即是 gbk)的字符流:
InputStream is = getClass().getResourceAsStream("/encoding/gbk_demo.txt");
Reader reader = new InputStreamReader(is, "gbk"); // 注意此处第二个参数为 gbk
不过 InputStreamReader 本身的 API 依然不是很好用, 这里用它主要是为了显式传入编码的参数, 之后可以进一步用 BufferedReader 包装, 以使用其 readLine 方法, 完整结果如下:
@Test
public void testReadByReader() throws Exception {
InputStream is = getClass().getResourceAsStream("/encoding/gbk_demo.txt");
Reader reader = new InputStreamReader(is, "gbk");
BufferedReader br = new BufferedReader(reader);
assertThat(br.readLine()).isEqualTo("hi你好");
}
字节流 vs 字符流
如果一下子就把整个文件读取上来, 那么通过以上两个示例, 可以看出使用字节流和字符流的差别并不大. 但假如现在有一个多行的文本文件, 然后打算一行一行地读取, 读一行就打印一行, 那么使用字符流就很方便, 比如 BufferedReader 它有一个 readLine 方法, 让你可以一下子读取一行.
但如果使用字节流呢? 那就麻烦很多了. 你要自己去读取并判断换行符的位置, 然后自己去断行.
糟糕的是, 不同系统下生成的换行符还可能不同. 比如 Windows 是
\r\n(0a 0d), 其它的一般为\n(0d).
另一方面, 假如想一个一个字符的读取, 字符流也有很好的支持, 比如像这样:
InputStream is = getClass().getResourceAsStream("/encoding/gbk_demo.txt");
reader = new InputStreamReader(is, "GBK");
char c = (char) reader.read();
assertThat(c).isEqualTo('h');
c = (char) reader.read();
assertThat(c).isEqualTo('i');
c = (char) reader.read();
assertThat(c).isEqualTo('你');
c = (char) reader.read();
assertThat(c).isEqualTo('好');
使用 Reader 下面的 read 方法, 每 read 一下就读取上来一个字符.
但使用字节流就很麻烦了, 因为很多编码它不是定长的, 就比如前面的这个例子, 前面两个字符 hi 各使用一个字节保存, 而后面的两个汉字则各使用两个字节保存.

所以要读取这四个字符, 前面两个你每读一个字节就要构建一个字符, 而后面两个你一下读取两个字节后才能构建一个字符.
那怎么区分什么时候要读取一个字节, 什么时候又要读取两个字节呢? 那么你就得理解 gbk 的编码方式.
gbk 编码它是兼容 ascii 的, 是变长编码, ascii 字符都是一字节, 二进制形式最高位都是 0;
而汉字字符用两字节, 首字节高位是 1, 第二个字节高位通常也是 1.(但也有为 0 的)

这就是 gbk 编码的模式, 你得理解这些编码的细节才能按字节去读取它们.
假如要读取的是 utf-8 的文本文件呢? 它也是变长编码, 有的字符是一字节, 有的是两字节, 有的是三字节, 有的是四字节.
假如现在有一个 utf-8 的字节流要你去读取, 那么你就得很清楚什么时候要读一字节, 什么时候又要读三字节. 你要非常清楚 utf-8 编码的规律, 各种不同字节间如何去区分.
假如现在你有一个 utf-8 编码的 txt 文件, 内容同样是 "hi你好", 那么它的十六进制形式是这样的:

它也是兼容 ascii 的, ascii 也是一字节;但对于常用汉字, 都是三字节编码. 具体的二进制则是这样:
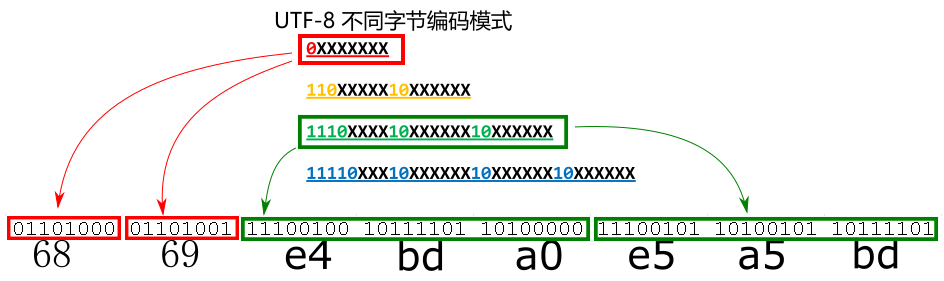
你要按字节读取它, 就要熟知一字节是什么模式(如上, 以 0 开头), 三字节又是什么模式(如上, 首字节以 1110 开头, 后接两字节以 10 开头).
所以你看, 如果采用字节流的方式, 是不是特别麻烦? 你要读取一个字节上来, 然后判断它是不是 0 开头, 是不是 110 开头, 是不是 1110 开头等等, 然后再进一步决定下来还要读取多少字节才能构成一个字符, 特别的麻烦.
而字符流呢? 我们说了, 它是针对文本文件对字节流的一个抽象与封装, 为方便我们读取文本文件而设计的.
有了它, 这些个麻烦事都不用我们去操心了, 你只要在构建字符流时给它一个字节流并告诉它这个字节流所使用的编码就行了, 它就知道怎么去断这些字节, 这些编码的知识都封装到它里面去了, 别人已经实现了, 不用我们去管.
所以, 读取文本文件, 特别是逐个字符的读取, 应该采用字符流.
不同编码的字符流
通过以上的一些示例, 相信对于前面所说的 字符流=字节流+编码 你应该有了更好的理解. 这里所谓的编码就是指相应文件保存时所使用的编码.
假如你读取的文件是 utf-8 编码的, 那么构建字符流时的编码参数就要传 utf-8:
@Test
public void testReadByReaderUtf8() throws Exception {
InputStream is = getClass().getResourceAsStream("/encoding/utf8_demo.txt");
Reader reader = new InputStreamReader(is, "utf-8"); // 此处编码需与文件的编码相同
BufferedReader br = new BufferedReader(reader);
assertThat(br.readLine()).isEqualTo("hi你好");
}
Reader 是读取, 而对于写入的 Writer, 原理也是一样的. 如果你想用 gbk 编码保存一段字符串, 你就构建一个 gbk 的写入字符流, 比如这样:
@Test
public void testWriteByWriter() throws Exception {
FileOutputStream fos = new FileOutputStream(new File("gbk_write_demo.txt"));
OutputStreamWriter writer = new OutputStreamWriter(fos, "gbk");
writer.write("hi你好");
writer.close();
}
那么写入到硬盘中的文件的编码就是 gbk, 就像你使用记事本另存为时选择编码为 gbk 那样(具体为选择 ANSI).
你不用去操心什么字符要写入一字节, 什么字符又要写入两字节, 都不用你管了. 你就操作那些抽象的"字符"就可以了, 不用管字节的事.
而如果你构建的是 utf-8 的写入字符流, 那么同样的, 最终写入到硬盘中的文件的编码就是 utf-8, 就像你使用记事本另存为时选择编码为 utf-8 那样.
不过要注意, 记事本的 utf-8 是带 BOM 的, 而这里的是不带 BOM 的, 除非你显式加入 BOM.
由于篇幅关系, 关于使用缺省编码的例子及对于"到底怎样才算一个字符"的分析留待下篇再谈.