
在上一篇中比较了使用字节流和字符流来读取(写入)文本文件的优劣后, 这一篇主要探讨缺省编码这个主题.
字符流使用缺省编码
通过前面的例子, 已经得出了一个结论: 字符流=字节流+编码.
可以在构建字符流时显示传入编码参数, 那么所得到的字符流就会以该编码来**编码(encode)或解码(decode)**字节流, 这会给文本数据处理带来极大方便.
但有时, 构建字符流时也可以不传入编码参数, 比如如下直接构建一个 InputStreamReader :
@Test
public void testReadByReaderDefault() throws Exception {
InputStream is = getClass().getResourceAsStream("/encoding/utf8_demo.txt");
//Reader reader = new InputStreamReader(is, "utf-8");
Reader reader = new InputStreamReader(is);
BufferedReader br = new BufferedReader(reader);
assertThat(br.readLine()).isEqualTo("hi你好");
}
对比注释掉的代码, 可以看出此时只用了字节流, 没有指定编码.
那么这时它到底是以什么编码来解码(decode)它要读取的字节流呢? 比如上面的 utf-8 编码的文本文件它能否正常读取呢? 我们想知道, 编码参数是必要的吗? 如果没有指定, 它是否会自动猜测出正确的编码呢?
这里先给出结论, 那就是编码参数是必要的, 是 decode(或 encode)所必不可少的, 之所以可以省略那是因为系统会为我们提供缺省值.
然后, 它也不会去自动猜测. (至少这里的 BufferedReader 之类的不会去猜测, 如果你使用其它的第三方增强的工具类, 那就未可知)没有指定它就用缺省去 decode(或 encode).
那么, 这就可能导致一个问题. 比如现在要读取的文件是 utf-8 编码的, 而假如系统的缺省编码值是 gbk 的话, 显然, 它将不能正确地解码!
缺省编码来自哪里?
但是, 系统的缺省编码到底是什么呢? 这个缺省值可以通过这样来得到:
import java.nio.charset.Charset;
public class DefaultEncoding {
public static void main(String[] args) {
System.out.println("defaultCharset: " + Charset.defaultCharset().toString());
System.out.println("file.encoding: " + System.getProperty("file.encoding"));
}
}
也就是用 Charset.defaultCharset() 或 System.getProperty("file.encoding") 的方式可以得到它.
当我在本地的 Windows 系统执行这段程序时, 结果如下:

缺省编码是 gbk.
而当我把这个 class 类上传到云主机时, 那是个 linux 系统(具体为 centos 7), 再执行时发现结果又不同了:

此时的结果是 ASCII(ANSI_X3.4-1968 是它的一个别名). 不同系统, 甚至不同版本这个值可能有很大差异, 跟具体的环境配置也有关, 在你的 linux 系统里可能输出是 utf-8 等值.
如果你用的是 Mac, 你也可以试一试看看结果是什么. (我没有 Mac, 所以没有测试这个~)
不过可以通过增加运行参数调整这个值, 比如以这样的方式
java -Dfile.encoding=utf-8 DefaultEncoding
来运行, 缺省编码就变成 utf-8 了:

在 linux 系统上也是同样的:

而我在 Windows 系统下的 Eclipse 工程里用它的"运行"来做这个测试时, 结果是 UTF-8 而不是 GBK, 因为工程我设置了缺省编码是 UTF-8, 而 Eclipse 运行时会根据你工程设置传入这个参数.
具体如下, 在 Debug 视图中, 选中运行的实例–右键–选择"properties", 在弹出的窗口中的 Command Line(命令行)部分可以看到指定了编码:
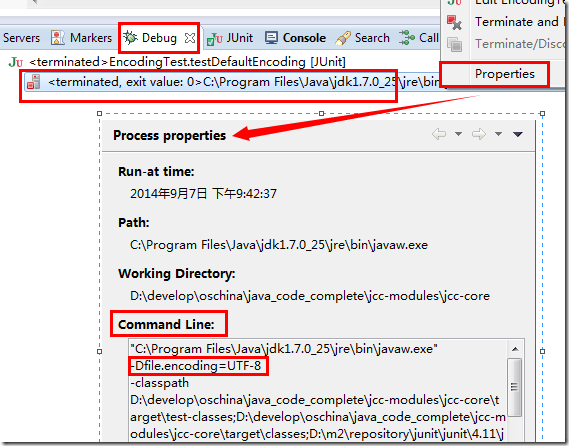
如果你工程指定的编码是 GBK 或没有指定, 在 Windows 下输出结果就会跟在 CMD 命令行窗口中那样, 结果应该为 GBK.
在 Idea IDE 中也是类似的, 比如工程编码是 GBK, 那么运行出来的结果也是 GBK:
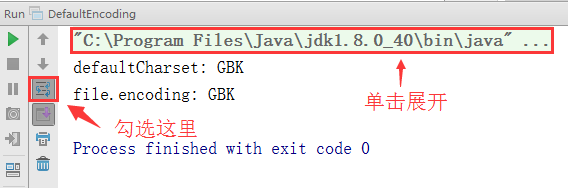
在上图中, 勾选"use soft wraps"(使用软换行),
这里因为是这个生成的命令行特别长, 主要是那一堆的 classpath, 跟 eclipse 类似, 所以让其换行显示.
然后单击所运行的命令展开它的细节, 可以发现也传入了相关 file.encoding 参数:
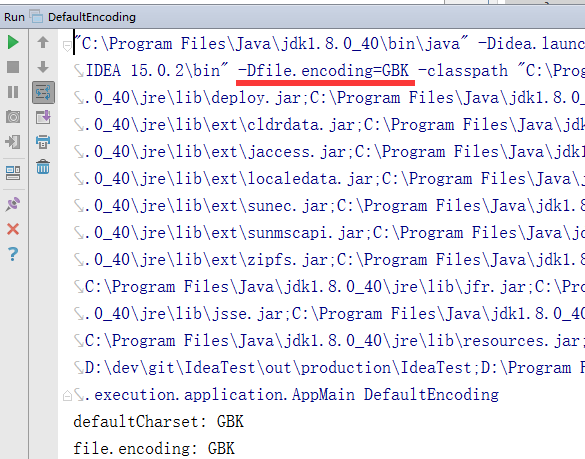
这个参数决定了缺省值是什么. 如果你没有指定, JVM 将询问它所在的运行环境(一般也就是操作系统了)来得到一个缺省值.
如果你运行 web server 的程序, 比如 tomcat, 也可以照此查看它的参数, 或通过它改变缺省值. 通过显式指定一个缺省值, 可以在各种运行环境下保持一致.
比如这是我本机 Eclipse 上运行 tomcat 插件时的命令行:
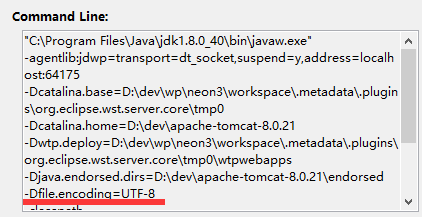
可以看到也是传入了这个参数. 不过有一点要注意的是, 至少就 server 中的这个缺省值而言, 它影响的是上述所说的 new InputStreamReader 以及 getBytes 之类的方法.
而在 servlet 的响应流中, 如果使用 response.getWriter 得到的 PrintWriter 这个字符流, 它的缺省又是另外一个值, 具体为 iso-8859-1.
这个缺省值来自于 servlet 的规范, 进一步的原因则是来源于 http 规范. 关于这一话题将在另一篇文章中再去分析.
所以, 总体而言, 如果你构建字符流时使用缺省编码, 那么情况会比较混乱, 也很容易出错.
使用缺省编码去读取
现在来看一些具体的例子. 假如要读取的还是之前那个 utf-8 编码的文本文件, 内容还是 "hi你好", 总计 8 个字节, 具体十六进制如下:

写一段读取它的程序如下:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.Reader;
public class DefaultReader {
public static void main(String[] args) throws Exception {
File f = new File("utf8_demo.txt"));
Reader reader = new InputStreamReader(new FileInputStream(f));
BufferedReader br = new BufferedReader(reader);
System.out.println(br.readLine());
br.close();
}
}
然后在 CMD 中编译并运行, 那么结果是这样的:

可以看到出来的并不是想要的 "hi你好", 而是很奇怪的 "hi浣犲ソ ". 那么其中的原因也不难理解, 因为没有指定编码, 所以程序就用缺省编码去解码这段字节流, 此时是 gbk, 所以就把那六字节按每两字节去解析, 结果得到三个汉字:

对于我们中国人来说, 会意识到出了问题, 因为这三字很不常见, 但对于歪果仁来说, 他可能没有什么感觉, 就是一些方块字而已, 反正他都不认识.
假如现在显式指定 –Dfile.encoding=utf-8, 那么结果就 OK 了:

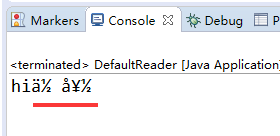
又假如指定为 –Dfile.encoding=iso-8859-1 呢? 那么结果就按 iso-8859-1 解析了:

这里它显示为六个问号, 其实正常来说, 应该是有对应字符的. 如果在 eclipse 本身执行, console 中的输出是这样的:
所以显示为问号可能是 CMD 程序本身的一些问题.
毕竟, 前面也一再提到, 文本文件内容本身是不包含有编码信息的(BOM 的情况除外), 就这么 8 个字节, 你有很多的解析可能, 按 gbk, 按 utf-8, 按 iso-8859-1, 都能解析出一些字符来.
总结
由此也不难明白, 缺省绝对不是什么好主意. 假如你不知道别人启动 web server 时传入了什么参数, 或者没传参数时你不知道程序到底运行在什么操作系统上, 你就完全无法预料你的程序会运行出什么结果.
通常, 我们把这种情况称为对环境形成了依赖, 是种不稳定因素. 程序员在开发活动中常遇到的一种情况是: "在我这里运行明明是正常的, 怎么放到其它地方去就不正常了呢? "就有可能是这种环境差异导致的.
假如你想把这段字节流稳定地解析成"hi你好", 那么最好的方式就是在你的代码里显式构建 utf-8 的字符流, 而不是依赖缺省.
当然, 有人可能会说, 每次都要显式指定, 我觉得太麻烦了, 我还是希望用缺省, 那么这种情况你就要保证所有环节都使用统一的编码, 比如所有你要读入的文件都是用这一编码去编码的等等, 然后用 –Dfile.encoding 参数指定这一编码. 假如你无法保证在所有环节统一, 恐怕你就不能如此依赖缺省了.
关于字符流使用缺省编码的话题就讨论到这里. 在最后一篇, 将讨论最后的一个话题: 到底怎样才算是一个‘字符’?