
在之前谈了很多关于 字符集编码与乱码 的基础知识, 可以说, 如果你掌握了这些, 对于各种乱码问题, 就有了一个良好的基础, 基本能够分析甚至独立地解决各类的乱码问题.
自然, 基础问题的重要性无需多言, 但另一方面, 具体的问题也同样很重要. 据我的观察, 具体的问题有很多是关于 web 开发方面所碰到的乱码, 尽管从原理方面来说, 道理都是一样的, 但导致问题产生的许多细节还是值得一说的, 所以这次也打算具体谈谈这些方面.
首先谈网页中的编码与乱码问题, 之后还会谈表单的编码, 后台接收参数时的解码与乱码, url(uri) 的编码与解码, 文件下载中文件名的编码乃至数据库中的编码等等.
这些具体问题的分析要建立在字符集编码基础知识之上, 所以, 如果你觉得自己在基础方面还不够扎实,
比如, 字符集与编码的联系与区别是什么? Unicode 具体是如何编码的? 几种 Unicode 编码实现间的联系与区别是什么? 什么是 UTF-16 的代理对等等,
如果你尚不能很清晰地回答以上一些问题, 那么我还是建议你先看看那些基础的介绍, 这样在分析 web 开发中遇到的具体编码及乱码问题时, 理解得会更好.
如何确定一个网页的编码?
现在开始讲网页的编码. 一个网页, 简单讲就是一个 html 的 文本文件. 那么如何去确定这样一个文本文件的编码呢? 在前面的 确定文本文件的编码--乱码探源(2) 和 引入编码信息的一些实践--乱码探源(3) 其实也谈到了几种方式:
如果你还不清楚如何去确定一个普通文本文件, 比如一个简单的 txt 文件的编码, 我建议你先看一看那两篇文章.
可以说, 确定一个网页的编码与那两篇文章中谈到的原理是一样的, 差别只是形式上的. 概括地讲, 确定网页的编码有以下几种方式:
- 缺省.
- 文档内的编码声明.
- 响应头中的 content-type 字段中的编码信息.
- BOM.
还有一种废弃的方式是在链接(link)中添加 charset 属性, 比如像这样一个 a 标签:
<a href="/mysite/mydoc.html" charset="iso-8859-1">
如果没有使用其它几种方式指定编码, 就会用这里这个值. 不过这种方式已经 不建议使用(deprecated), 这里稍微提一提它.
文档内的编码声明
稍微解析一下, 第一个缺省方式放到后面再说;第二个所谓"文档内的编码声明(in-document charset declaration)"指的是这样的(第4行):
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gbk">
<title>一个 GBK 编码的页面</title>
</head>
<body>
<h1>GBK encoding page with meta charset declaration</h1>
<p>这是一个 GBK 编码的页面,有设置 meta http-equiv 中的 charset 的值为“gbk”。</p>
</body>
</html>
<meta http-equiv="Content-Type" content="text/html; charset=gbk">
以上是 html4 中的标准写法, 声明了此文档的编码是 gbk.
又或者是这样的(第4行):
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>一个 UTF-8 的页面(带 meta 声明)</title>
</head>
<body>
<h1>a UTF-8 encoding page with meta charset declaration</h1>
<p>一个 UTF-8 的页面(带有 meta 声明)</p>
</body>
</html>
<meta charset="utf-8">
以上是 html5 中的标准写法, 声明了此文档的编码是 utf-8.
当然, 一个 html 文档不包含这些声明的情况也是有的, 但通常不建议你这么做. 一个具体示例:
<!DOCTYPE html>
<html>
<head>
<title>一个 GBK 编码的页面</title>
</head>
<body>
<h1>GBK encoding page without meta charset declaration</h1>
<p>这是一个 GBK 编码的页面,但没有使用 meta charset 声明。</p>
</body>
</html>
响应头中的 content-type 字段中的编码信息
而所谓的"响应头中的 content-type 字段中的编码信息",
首先你要知道怎么在浏览器中查看响应头, 作为一个 web 开发者, 我觉得你应该是知道的, 但防止有人说不知道, 就"帮人帮到底, 送佛送到西"吧, 具体点击这里了解: 在开发者工具中查看响应头的字符集编码信息. 至于更深层的什么 http 协议这些就恕不能详细展开, 否则没完没了, 三天三夜也讲不完...
指的是这样:
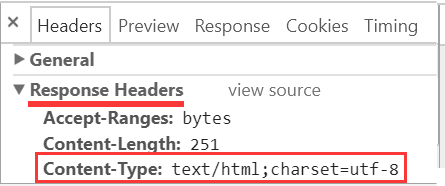
以上声明了响应文档流的编码是 utf-8:
Content-Type: text/html; charset=utf-8
又或者是这样:
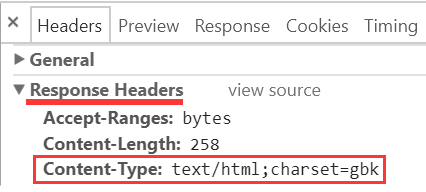
以上声明了响应文档流的编码是 gbk:
Content-Type: text/html; charset=gbk
显然, 不难发现, 这跟前面的文档内的编码声明 html4 中的 meta http-equiv="Content-Type" 非常类似, 不同之处是它是文档外而不文档内的.
当然, 响应头中也可能没有编码信息, 像这样:
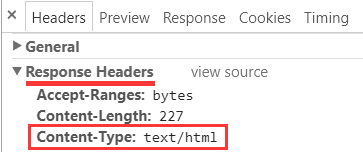
甚至连 Content-Type 这个条目本身也没有也是可能的:
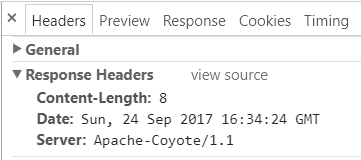
在后面, 还会具体介绍如何去设置这个 Content-Type 的值.
BOM
而所谓 BOM, 如果你不了解什么是 BOM, 先看这里的基础知识:
具体以一个 UTF-8 的 BOM 来说吧, 就是响应流中的开头的前三个字节, 它们是 EF BB BF, 这就是 UTF-8 的 BOM. 如果有 BOM, 就能直接知道对应的编码, 无需 header 中的指示, 也无需用嗅探方式尝试获取流中包含的 meta charset 或 meta http-equiv="Content-Type" 信息.
缺省
最后, 缺省方式就是以上几种方式都失效时的兜底方案, 没有 BOM, 没有 header, 没有 meta, 浏览器只好"蒙"一个编码, 当然也不是瞎蒙, 通常跟系统语言地区设置有关, 具体情况后面再说.
使情况变得复杂的是, 几种方式有可能同时存在, 比如文档内存在编码声明, 同时响应头中也有编码信息.
使情况更加复杂的是, 这两个信息可能是冲突的, 比如文档内的 meta 声明说编码是 GBK, 响应头中的 content-type 却说编码是 UTF-8, 那么浏览器此时该如何抉择呢? 这就涉及到置信度或者说优先级的问题了.
多方式并存且存在冲突时的优先级
这里先给出一个结论, 如果多方式并存, 且给出的编码信息不一致, 通常按这样的优先级来取舍:
- BOM
- 响应头编码
- 文档内编码声明
也就是 BOM 的优先级是最高的, 其次是响应头的, 文档内编码声明的优先级最低.
而所谓通常, 指新近的浏览器会按这样的方式处理, 而较老版本的浏览器则可能有所偏差.
事实上, 协议本身在不断完善, 而各种浏览器实现众多, 版本也不断推陈出新, 加上实现人员对协议理解可能存在偏差等等原因, 这个问题想给个确切结论是比较困难的. 如果你觉得我说得有问题, 也不必急着反驳.
鉴于现实存在的困难, 我一向认为, 结论本身并不是那么重要, 重要的是你是怎样通过实验, 观察及对规范方面的参考得出上述结论的. 有句话说: "授人以鱼不如授人以渔", 我将具体介绍如何通过实验分析得出上述结论, 而不单单是结论本身.
自然, 这样会使得篇幅更长, 但我认为这是有意义的. 我经常看到一些人提出他们碰到了乱码问题, 然后对此毫无头绪, 或者解决起来毫无章法, 很多时候甚至就是瞎蒙乱试一通, 运气好也许就解决了, 运气不好时反反复复折腾都无法解决.
糟糕的是, 很多人甚至不知道应该提供什么信息以利于别人排除某些可能性, 缩小分析范围, 最终帮他们聚焦到真正的问题上. 很多时候这些问题就是简单一句话: "我碰到乱码了, 我该怎么办? "即便能大概猜到是怎么回事, 但很多时候还是需要具体问题具体分析的, 而他们提供的信息又太少, 所以碰到这些问题我通常也不愿意去回答.
所以, 在后面我会尽量呈现分析一个编码及乱码问题的完整过程, 希望能有所启示. 接下来将一一通过具体示例(包括静态页面和动态页面)具体分析以上几种情况, 以及存在冲突时的取舍. 鉴于篇幅问题, 具体分析留待下篇再说, 欢迎继续关注.