
这一篇将介绍 BOM 在 html 页面编码中的运用. 在最前面曾提到, 它的优先级实际上是最高的, 在这里, 将具体介绍什么是 BOM, 还会解析为什么它的优先级最高, 然后还会构建一些具体的测试来验证这一点.
什么是 BOM?
关于什么是 BOM, 在这篇文章中有详细的介绍:
这里也稍微啰嗦几句, 内容也基本出自上述文章: BOM=Byte Order Mark, 翻译过来就是"字节顺序标识".
具体则分为两种: 小端序(Little endian) 和 大端序(Big endian).
我们知道, 在记事本中 "另存为" 时可以选择编码, 有以下几种:
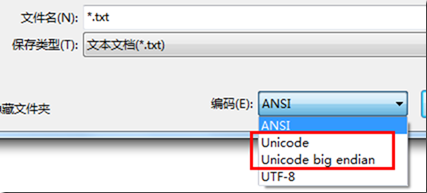
这里的 Unicode 实际就是 UTF-16(小端序).
注: Java 平台中 UTF-16 缺省为 大端序, 与 Windows 恰好相反.
另: 记事本的 UTF-8 默认是带 BOM 的, 而多数 IDE 的编辑器 UTF-8 默认不带 BOM.
在记事本中以 ANSI 之外的三种编码分别保存一下 "hello你好", 分别命名为:
- UTF16BE.txt
- UTF16.txt
- UTF8.txt
分别对应以下三种编码:
- Unicode big endian
- Unicode
- UTF-8
查看三个文件的十六进制形式, 结果是这样的:

这三个文件中最前面红框中的字节就是所谓的 "BOM", 它不是具体内容 "hello你好" 的一部分, 而是一个额外的特征值.
从上图的红色箭头不难发现, UTF-16 大小端之间, 两两字节间顺序恰好相反. 对于 UTF-16 字节流而言, 开头的 BOM 是必须的, 因为它指示了字节流到底是大端序还是小端序, 如果弄反了, 整个字节流的内容就会面目全非.
而对于 UTF-8 而言呢? 实际上却不存在字节序, 或者说它只有大端序, 就一种字节序. 所以, 对 UTF-8 而言, BOM 是可以省略的, 对于它而言, 我们常说的它是"带 BOM"还是"不带 BOM", 而不是说它到底是什么端序. 更多时候它的 BOM 是作为字符集编码的标志, 因为只要看到这样的 BOM, 就知道它是 UTF-8 编码.
下图是各种 BOM 的一个汇总(图片截取自unicode.org):
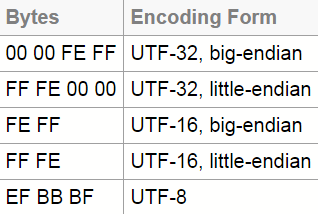
BOM 其实就是 U+FEFF 这一码点, "EF BB BF"就是这一码点在 UTF-8 下的编码. 测试代码如下:
import java.io.UnsupportedEncodingException;
import org.junit.Test;
import static javax.xml.bind.DatatypeConverter.printHexBinary;
import static org.assertj.core.api.Assertions.assertThat;
public class BOMTest {
@Test
public void testBomCodePoint() throws UnsupportedEncodingException {
String s = "\uFEFF";
assertThat(printHexBinary(s.getBytes("UTF-8"))).isEqualTo("EFBBBF");
}
}
为什么 BOM 的优先级最高?
显然, BOM 其实类似于文档内编码声明, 不同之处则在于它是由文本编辑器控制写入的, 而且是置于文档的最开头处.
假如说你选择了保存为 UTF-8 带 BOM 的编码, 文本编辑器就会在内容之前添加"EF BB BF"三个字节, 然后之后的内容也一定是用 UTF-8 来编码的. 不会发生在"文档内编码声明"中那种错误声明的情况.
这种一致性是由编辑器为我们保证的, 除非你直接修改那些最终的二进制的值, 否则这种宣称的 BOM 与实际所用的编码的一致性是能得到严格保证的.
换言之, 就是它的置信度是最好的, 所以它的优先级最高也就不难理解了.
带 BOM 的静态页面测试
如下构建了一个带 BOM 的静态页面,
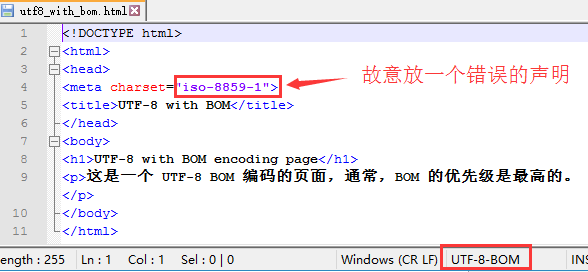
下方编码处的值"UTF-8-BOM"表明了它的实际编码, 页面还故意带了一个错误的 meta 声明.
Eclipse 的 编辑器不支持把 UTF-8 保存为带 BOM 的, 这个需要用记事本或 notepad++ 这样的编辑器来完成. 不过 Eclipse 中的编辑器也能正常识别带 BOM 的 UTF-8 编码的页面.
header 也故意用 gbk 编码来添乱:
<mime-mapping>
<extension>html</extension>
<mime-type>text/html;charset=gbk</mime-type>
</mime-mapping>
但由于 BOM 的优先级最高, chrome 浏览器还是能正常打开:
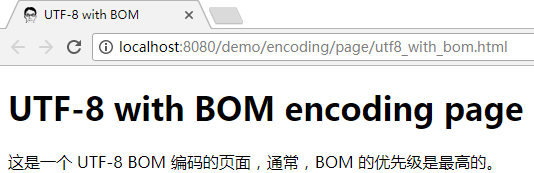
不过在 IE 下的测试却没有通过, 它还是采用了 header 中建议的值来解析, 从而导致了乱码:
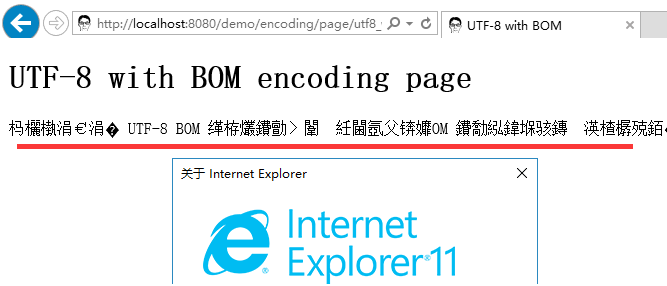
但是像 Firefox, Edge 这些较为现代的浏览器都能正常:

表明它们都遵循了 BOM 优先的建议, IE 则是个例外.
这也表明了事情可能要比我们想象的要复杂.
带 BOM 的动态响应测试
同理, 也不难构建一个动态的带 BOM 的 UTF-8 响应, 同样设置了很多的干扰因素:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/bom/utf8")
public class EncodingBomUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=gbk"); // 干扰因素 gbk
ServletOutputStream os = response.getOutputStream();
String bom = "\uFEFF";// UTF-8 byte order mark (EF BB BF)
String meta = "<head><meta charset=\"iso-8859-1\"></head>"; // 干扰因素 iso-8859-1
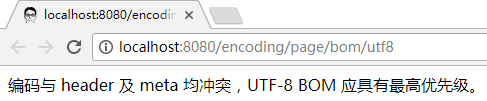
String contentWithBom = bom + meta + "编码与 header 及 meta 均冲突,UTF-8 BOM 应具有最高优先级。";
os.write(contentWithBom.getBytes("utf-8")); // 带 bom 的 utf-8
}
}
前面说到: BOM 其实就是 U+FEFF.
浏览器还是能够通过测试:
用 UTF-16 也是可以的:
@WebServlet("/encoding/page/bom/utf16")
public class EncodingBomUTF16 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=gbk");
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"iso-8859-1\"></head>";
os.write((meta + "编码与 header 及 meta 均冲突,UTF-16 BOM 应具有最高优先级。").getBytes("utf-16"));
}
}
注意: getBytes("utf-16") 生成的字节流数组会自动带上 BOM, 这里不需要手动像 UTF-8 那样添加 BOM. 前面也说了, 对 utf-16 来说, BOM 是必不可少的.
测试也 OK:

不过如果你明确写成 getBytes("utf-16le") 或 getBytes("utf-16be"), 那么生成的字节流数组就不会带上 BOM 了, 这时你要自己在前面加入 BOM, 像 UTF-8 时那样:
@WebServlet("/encoding/page/bom/utf16le")
public class EncodingBomUTF16LE extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=gbk");
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"iso-8859-1\"></head>";
String bom = "\uFEFF";
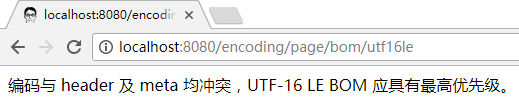
os.write((bom + meta + "编码与 header 及 meta 均冲突,UTF-16 LE BOM 应具有最高优先级。").getBytes("utf-16le"));
// 也可以手动输出 bom,不过注意小端序要按 ff fe 的顺序。
// os.write(0xff);
// os.write(0xfe);
// os.write((meta + "编码与 header 及 meta 均冲突,UTF-16 LE BOM 应具有最高优先级。").getBytes("utf-16le"));
}
}
结果也是 OK 的:
你可以始终用那个转义的 \uFEFF 来表示 BOM, 但如果你决定手动输出字节(图上注释代码部分), 就要注意小端序时的顺序, 否则输出结果将会是面目全非.
关于 BOM 编码的介绍就到这里, 最后一篇将谈谈剩下的最后一种情况, 也即是"缺省"情况, 并最终做个总结.