
接着 上一篇中的讨论, 也是先从"文档内编码声明"讲起, 因为它是最直观也最容易控制的.
不过事实上也没有那么容易, 它还是很容易受各种因素干扰, 下面会详细介绍整个过程, 囊括了静态文档响应和动态文档响应两种情况, 以及各种其它注意事项.
文档内的 meta charset 编码声明
通过之前的介绍, 你已经知道了所谓的文档内 meta charset 声明:
<meta charset="gbk">
以上为 html5 的标准写法. 又或者这样(html4)
<meta http-equiv="Content-Type" content="text/html; charset=gbk">
在静态文档中的实验
假如现在有两个文档, 一个声明是 gbk 的:
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk">
<title>一个 GBK 编码的页面(带 meta 声明)</title>
</head>
<body>
<h1>GBK encoding page with meta charset declaration</h1>
<p>这是一个 GBK 编码的页面,有设置 meta charset 的值为“gbk”。</p>
</body>
</html>
一个是 utf-8:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>一个 UTF-8 的页面(带 meta 声明)</title>
</head>
<body>
<h1>a UTF-8 encoding page with meta charset declaration</h1>
<p>一个 UTF-8 的页面(带有 meta 声明)</p>
</body>
</html>
然后都正确按照了所声明的编码保存.
这里特别要注意的一点是, 有的时候, 不是说你声明了某个编码, 你的文档就会自然而然地就用这个编码来保存. 这个一致性是要由源码的作者来保证的. 详情见本文后面的章节.
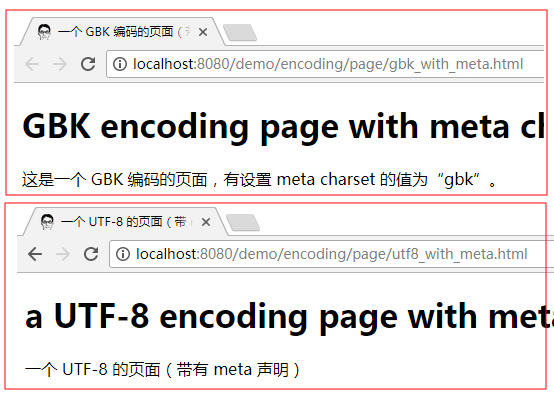
之后部署然后在浏览器中打开它们, 正常情况下应该都能正确显示:
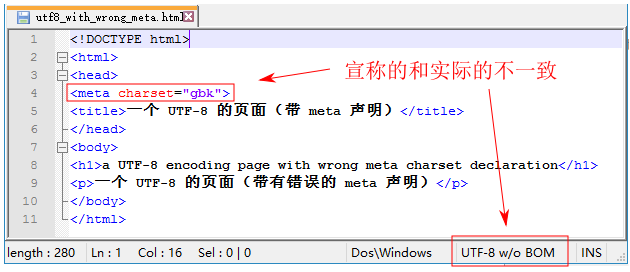
如果两者不一致, 那么结果将会是乱码. 比如下面的页面 meta 宣称是 gbk 编码, 实际保存所用的却是 utf-8:
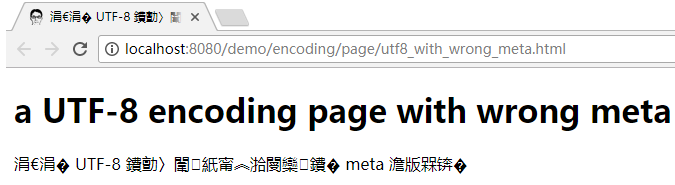
当在浏览器中打开时, 将发生乱码:
实际上, 这个文件在 IDE 中, 比如在 Eclipse 中打开时也是乱码的:
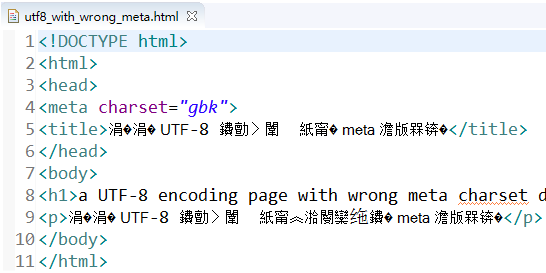
因为较为智能的 IDE html 编辑器在打开这个文件时会参考里面 meta 声明的值来解码, 反而被误导了, 跟浏览器类似.
事实上, 智能的 IDE html 编辑器在保存时也会参考 meta 声明的值来选择保存时的编码. 这种不一致的情况要在外部的简易编辑器中去构建, 比如上面的 notepad++ 编辑器, 更具体的一些介绍参考本文后面的章节.
在某些浏览器中, 发生乱码时你可以手动的调整编码以获取正确的显示:
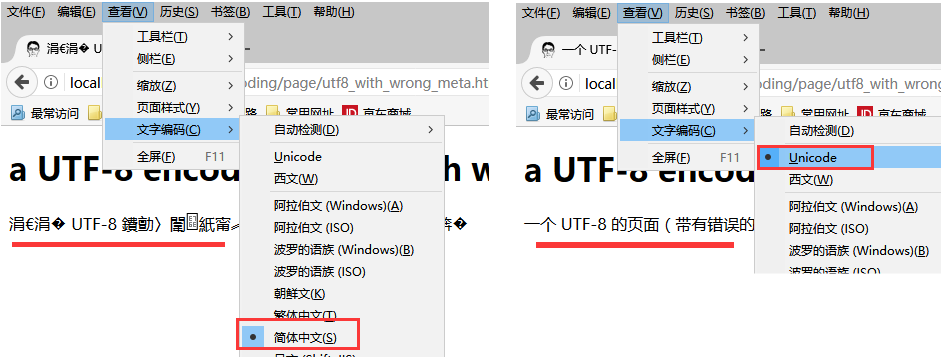
如上, 开始是乱码的, 此时展开"菜单--文字编码"会发现选在了 "简体中文"一项上, 这正是 meta 中的建议, 但很不幸它是错误的建议;修正为 Unicode 后将获得正常的显示结果.
当然, 以上实验里要保证一点, 那就是响应头中 Content-Type 不应该有 charset 信息. 前面说到, 它的优先级是要高过文档内编码声明的.
实验中的一项重要原则就是: 隔离. 要确保变量是受控的, 这样才能得出可靠结论.
所以, 进行上述实验时请确保响应头中没有编码声明, 像这样:
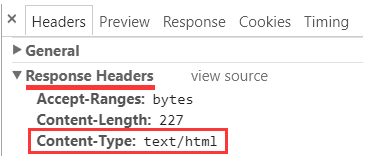
或者甚至连 Content-Type 条目本身也不出现.
我实验用的是 tomcat8 这个 web server, 对于静态页面, 缺省配置下, 它不会试图往 Content-Type 中塞入 charset 信息. 事实上, 它下面可能有非常多的页面, 哪个哪个用了什么编码来保存的它也不知道. 前面还说过, 文本文件中保存后经常是 不包含 编码信息的, 具体参见:
一个文本文件最终也是一个字节序列, 对于静态文件请求, tomcat 它只要把你请求的文件一字节一字节发到浏览器端就完事了, 它根本不会操心这些字节到底是什么编码. 这一过程跟 FTP 下载文件没有什么本质区别, 就是一个简单的复制传输过程.
那你可能会好奇, 那有时不是响应头中 Content-Type 还带有 charset 信息吗? 这难道不是 tomcat 尝试去获取后并告诉我们的? 还真不是. Content-Type 的 charset 信息是一个"配置"的值, 是由我们指定的.
具体如何在 server 或项目中去配置它, 后面讲到 Content-Type 中的 charset 声明时再具体说.
现在假如你为所有的 html 响应配置了一个全局的 Content-Type, 其中 charset 值为 utf-8, 像这样:
Content-Type: text/html; charset=utf-8
那么这时你再次请求先前正常的 gbk 文档时就会发生乱码:
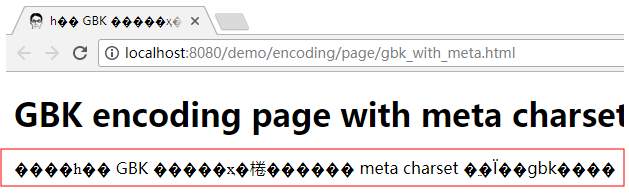
因为它的优先级要高过文档内的声明:
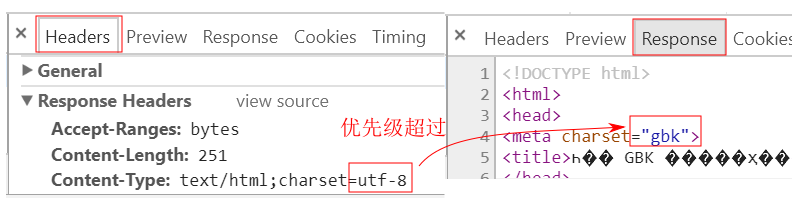
如果草率地配置一个全局性的带 charset 的响应头, 是有可能带来混乱的!
而你请求那个原本正常的 utf-8 文档时就不会有问题, 虽然浏览器还是优先采用这个响应头中的声明, 但它也正好与文档内的声明一致, 所以不会有问题.
事实上, 此时请求那个原本因不一致而不能正常显示的页面此时却也正常了, 因为响应头的编码盖过了那个错误的 meta 声明, 而又恰好与实际所用编码一致, 所以反而正常了.
这时, 反而是掩盖了实际存在的问题! 所以, 多种方式并存并相互影响的实际会让事情变得很复杂.
那么以上就是静态文档中实验, 就介绍到这里.
动态文档中的实验
除了静态方式, 还可以动态的构建一个 html 响应. 这时服务端并不存在一个具体的 html 文件, 一切都是动态生成并实时发送到浏览器客户端.
这样的技术有很多, 什么 php, asp, jsp, 不管什么 p, 简单讲, 最终还是生成 html.
在 Java Web 中, 可以使用 servlet 或 jsp(本质上也是 servlet) 的方式, 还可以灵活地控制响应头信息. 比如像下面这样:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/rightMeta/gbk")
public class EncodingRightMetaGBK extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html");
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"gbk\"></head>";
os.write((meta + "编码与 meta 一致,GBK.").getBytes("gbk"));
}
}
这里为简单起见, 往浏览器端的输出流中省略了 doctype, html 根元素, body 元素等, 一般情况下你应该包含一个 html 文档的完整结构, 像前面那些静态文档那样. (但这种情况下在 servlet 中直接构建响应流会特别繁琐, 这也是 jsp 这些模板技术出现的原因. )
或这样:
@WebServlet("/encoding/page/rightMeta/utf8")
public class EncodingRightMetaUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html");
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"utf-8\"></head>";
os.write((meta + "编码与 meta 一致,UTF-8.").getBytes("utf-8"));
}
}
响应头中的 Content-Type 没有 charset 信息,
这里也可以直接用
response.setContentType("text/html")来达到同样目的.
浏览器依赖包含在输出流中的 meta charset 声明, 也能正确解析文档:
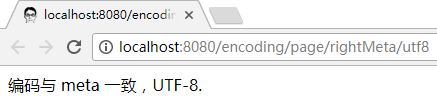
注意: 动态构建的文档你同样需要保证字节流与宣称编码的一致性. 这里具体就是 getBytes 中使用的编码要与 meta 声明的一致:
// 一致使用 gbk
String meta = "<head><meta charset=\"gbk\"></head>";
os.write((meta + "编码与 meta 一致,GBK.").getBytes("gbk"));
// 一致使用 utf-8
String meta = "<head><meta charset=\"utf-8\"></head>";
os.write((meta + "编码与 meta 一致,UTF-8.").getBytes("utf-8"));
如果不一致:
@WebServlet("/encoding/page/wrongMeta")
public class EncodingWrongMeta extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html");
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"gbk\"></head>"; // 声明用 gbk
os.write((meta + "编码与 meta 冲突,乱码。").getBytes("utf-8")); // 实际用 utf-8
}
}
同样会导致乱码:
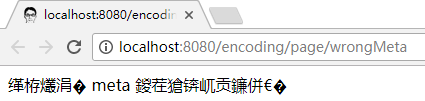
关于动态文档响应的实验就介绍到这里.
鸡生蛋与蛋生鸡的问题
看到这个小标题你可能有点困惑, 这是要讲什么? 其实当我们说到利用文档内的编码声明来解析文档时, 你是否有过一些疑惑呢? 我们打个比方来说吧:
假如你想打开一个锁着的箱子, 可钥匙却在箱子里锁着, 那你该怎么办呢?
文档内的编码声明跟这个有点类似, 注意这个"内"字, 编码信息是文档内容本身的一部分. 你想要正确的解析文档, 你首先要知道编码;而要知道编码, 你又要先解析文档...
所以这构成了一个死局, 关于怎么破解这个死局, 其实在之前的 引入编码信息的一些实践--乱码探源(3) 中有过介绍, 如果你感兴趣, 可以去看看, 其中还有一段利用正则表达式去获取编码信息的小程序示例.
简单讲, 就是先用所谓的"嗅探"加"猜测"的方式先做些尝试, 以尝试获取编码信息, 然后再用所获取的编码重新解析整个文档.
为提高嗅探的效率, html 规范建议 文档内的 meta 编码信息应尽量放在前 1024 个字节内. 简单讲, 就是你最好就把它声明在 head 标签的第一行, 在 doctype 声明前面也不要写太多的注释, 否则, 嗅探算法扫描了前 1024 个字节仍然没有找到 meta charset 声明的特征字节码时, 就可能放弃, 认为你的文档内没有包含编码声明.
其实像 xml 那样把编码信息声明在第一行是最好的:
<?xml version="1.0" encoding="UTF-8"?>
构建静态文档时的注意事项
在前面, 提到构建静态文档时有一些注意事项, 为保持行文紧凑, 没有过多展开, 现在在这里统一做个补充.
在现代智能的 IDE 中, 比如我用的 Eclipse, 它的 html 编辑器会关注你所用的 meta 声明. 如果你的文档中带有 meta 如下:
<meta charset="gbk">
那么它就会自动用 gbk 编码保存此文档, 即便所在工程的缺省编码是 utf-8 时也是如此. 还要注意文档中不能包含 gbk 不支持的字符.
如果加入了 gbk 不支持的字符, 则保存不了. 你可能好奇保存前为啥又还能显示呢? 这是因为保存前内容都存在于内存中, 在 Windows 系统中, 统一用 UTF-16 编码, 直到按下保存时才会转换成 gbk 的字节数组写入硬盘. 这也是你为何可以在不同编码间的文档中能互相拷贝内容的原因.
这样的一个好处就是保证了 "保存文档实际所用的编码与 meta charset 中宣称的编码一致".
如果你此时又把 charset 的值改为 utf-8, 则 html 编辑器又会按照这个编码保存文档.
你会注意到文件的大小发生了不小的变化, 这不仅仅是因为 "utf-8" 这个字符串本身比 "gbk" 多两个字符(5:3), 更重要是因为 gbk 用两字节保存一个中文字符, 而 utf-8 多数情况下用三字节保存一个中文字符, 所以如果原文档中中文字符较多, 最终文件大小就会发生较大变化.
注意, 如果以 gbk 保存后你又想把它构建成一个缺省的不带 meta 声明的 gbk 文档, 你不能简单地把 meta 信息删掉然后保存, 这时 Eclipse 会按工程的缺省编码(有可能是 utf-8)而不是之前保存所用的编码来保存. 这样你得到的有可能不是 gbk 编码的文档.
正确的做法是用其它的文本编辑器来保存, 那些可以让你选择编码的编辑器. 比如在 Windows 下你可以简单用记事本程序来做, 使用 "另存为" 在弹出的框中的编码一栏里选择缺省编码(ANSI)即可
Windows 大陆版缺省的 ANSI 就是指 gbk(或是能兼容 gbk 的).
另, 如果你在记事本中编辑一个 html 文档, 然后加入一个 meta charset 为 utf-8 的声明, 如下所示:
<meta charset="utf-8">
请特别注意, 记事本没有 IDE 中的那些专职的 html 编辑器那么聪明, 它不会按你这里声称的编码来保存(根本不知道这是什么鬼), 除非你用"另存为"然后显式选择 utf-8 编码(还要指出一点, 这里的 utf-8 是带 BOM 的~), 否则它就用缺省的 ANSI 也即是 gbk 来保存.
这样就导致了"实际所用编码与宣称的不一致", 而后将有极大概率误导浏览器的解析过程, 最终造成页面展示时的乱码.
所以, 在你亲自来进行实验时, 在你把文档交付给浏览器解析前, 请务必确保两者的一致性, 否则你的实验将建立在错误的前提下, 你将受到干扰, 无法得到可靠的结论.
如果你不确定你的文档实际到底用了什么编码, 终极的方式是查看二进制. 至少就 gbk 与 utf-8 的中文编码而言, utf-8 的二进制模式具有鲜明的特征, 这是由它的编码方案决定的, 与 gbk 的区分度还是非常大的.
关于 utf-8 与 gbk 这些编码特征的一些介绍, 参考 字符集与编码(四)--Unicode 和 字符集与编码(九)--GB2312, GBK, GB18030.
在 确定文本文件的编码--乱码探源(2) 里曾介绍了一个查看二进制的工具, 有兴趣可以去试试.
不过我现在发现这个二进制工具有时不太稳定, 有的情况下会把 gbk 错误转换成了 utf-8.
如果你能深入到二进制里, 了解这些模式, 了解两种编码的区别, 对你解决很多乱码问题会有很多帮助.
关于文档内编码声明的介绍就到这里, 下一篇将具体分析响应头中的编码信息及冲突时的优先级选择问题.