
在上一篇说完了如何 通过文档内的编码声明来确定网页的编码 通过文档内的编码声明来确定网页的编码, 这一篇则开始具体讲述如何通过响应头下的 Content-Type 条目中的 charset 信息来确定文档的编码, 包括如何去配置这个响应头, 以及一些具体的实验, 还有它与文档内编码声明的优先级选择问题.
content-type 中的 charset
通过前面的介绍, 你已经知道了所谓的"响应头下的 Content-Type 条目中的 charset 信息", 就是这样:
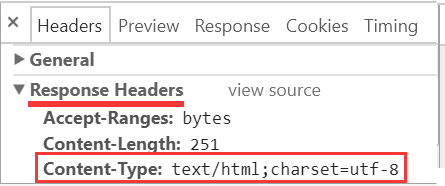
或这样的东西:
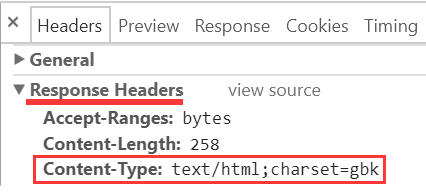
它指出了这段响应流的编码.
响应头的优先级为什么更高?
前面已经说到, 它的优先级是要高过文档内编码声明的. 这其实也很好理解, 因为它属于外部信息, 而文档内编码声明则属于内部信息.
上一篇说到, 浏览器还要通过嗅探算法才能获取到文档内的编码声明.
所以, 如果服务端的响应已经直接告诉你这段响应流的编码, 你都不用去"嗅探"了, 浏览器自然很乐意直接采用它.
也可以这样理解, 这个编码的头信息服务端是可以不发送的, 现在反而专门主动地告诉你, 怕你不知道, 自然它的可信度也是很高的. 浏览器优先采用它也不足为奇了, 还省略了嗅探的步骤, 提高了效率.
配置静态页面的响应头编码
前面说到, 当在 tomcat8 缺省配置下运行时, 它不会为 Content-Type 中增加编码信息:
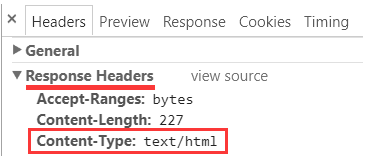
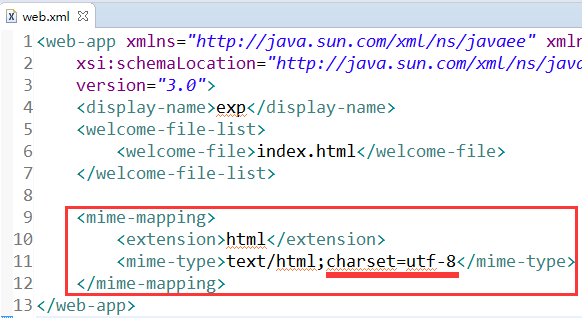
我们需要主动去配置这个信息. 具体而言, 可以去到工程的 web.xml 下, 在 web-app 根节点下增加一个 mime-mapping 配置:
<mime-mapping>
<extension>html</extension>
<mime-type>text/html;charset=utf-8</mime-type>
</mime-mapping>
这里, extension 表示文件的扩展名(后缀名), 而 mime-type 中的内容则成为 Content-Type 的值, 如此, 就增加了编码的信息.
web.xml 最终结果如下:
当然, 不同的 web server 间具体配置的语法会有所区别, 如果用的不是 tomcat, 你可以查询相应文档了解.
这样一来, 所有对 html 的静态请求, 响应头就会变成这样:
显然, 这样的一个配置是一个工程全局级别的,
注意: 如果你直接修改 tomcat server 的相关配置文件, 就会成为服务器级别的, 将影响它下面部署的所有工程!
这时你要保证工程下所有的 html 文件都是使用 utf-8 来编码的, 否则由于它具有更高的优先级, 那些比如 gbk 编码的文档将会发生乱码, 在上一篇中的实验中也已经证实了这一点:
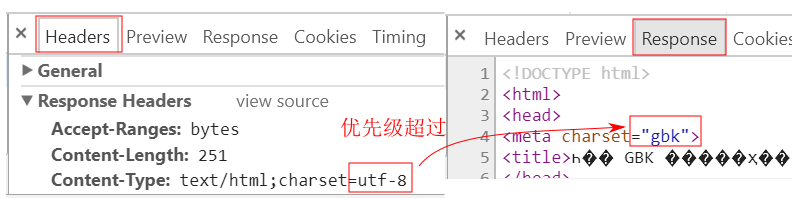
在开发实践中应该遵循"审慎"原则, 当你做某项调整时, 要清楚知道它的后果. 你不能光顾着解决自己当下碰到的问题, 还要留心是否会引发更多的问题, 也即是人们常说的 "按下葫芦起了瓢".
很不幸的, 碰到乱码问题时, 我们经常是"病急乱投医", 而这点又往往是因为我们对编码问题没有一个整体认识所导致的.
配置动态响应的响应头编码信息
如果说静态的响应头配置在 tomcat8 中显得还不是很灵活, 那么在动态的响应中, 你则可以自由地根据需要调整. 比如这样:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/rightHeader/utf8")
public class EncodingRightHeaderUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=utf-8");
ServletOutputStream os = response.getOutputStream();
os.write("编码与 header 一致,UTF-8.".getBytes("utf-8"));
}
}
或者这样:
@WebServlet("/encoding/page/rightHeader/gbk")
public class EncodingRightHeaderGBK extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=gbk");
ServletOutputStream os = response.getOutputStream();
os.write("编码与 header 一致,GBK.".getBytes("gbk"));
}
}
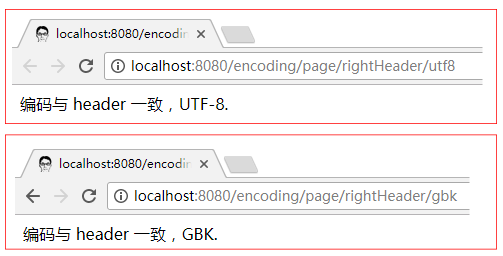
文档中也可以省略 meta charset 声明了. 当然, 现在你要注意的依旧是要保证宣称编码与实际所用的一致:
正如上面两段代码呈现的那样, 宣称是 utf-8, 实际也得是 utf-8;宣称是 gbk, 实际也得是 gbk.
不管是文档内的还是文档外的, 保持一致性才能避免乱码的发生. 以上两种情况下, 文档都能浏览器中正确显示:
假如不一致:
@WebServlet("/encoding/page/wrongHeader")
public class EncodingWrongHeader extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=gbk"); //宣称 gbk
ServletOutputStream os = response.getOutputStream();
os.write("编码与 header 不一致,乱码!".getBytes("utf-8")); //实际 utf-8
}
}
结局依然是乱码:
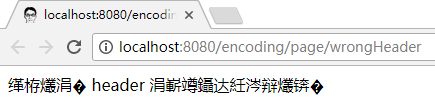
以上, 为每个请求都单独设置了响应头信息, 能够做到很灵活的设置. 但有时我们可能也不想处处都要这样弄一下, 对于动态响应, 同样可以对全局(或者更小一点的局部)做一个统一配置, 这点可以通过
filter来做到. 不过这些不是这里谈论的重点, 这里也是稍微提下.
优先级测试
通过动态响应, 很容易构建一个冲突的编码声明的例子:
@WebServlet("/encoding/page/rightHeaderWrongMeta")
public class EncodingRightHeaderWrongMeta extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html; charset=utf-8"); // utf-8 与 getbytes 一致
ServletOutputStream os = response.getOutputStream();
String meta = "<head><meta charset=\"gbk\"></head>";// gbk 与 getBytes 冲突
os.write((meta + "编码与 header 一致,与 meta 冲突,header 优先级高,结果正常。").getBytes("utf-8")); // 实际 utf-8
}
}
如上, Content-Type 中是 utf-8, 文档内声明 meta charset 是 gbk, 实际是 utf-8.
最终, 显示是正常的:

虽然 meta charset 给出了一个错误的建议, 但 Content-Type 的优先级更高, 浏览器先采纳了它, 忽略了文档内的声明.
反之, 如果优先级更高的 Content-Type 给出了错误的建议, 页面就会乱码了, 具体代码及演示略, 读者可以自行构建类似的测试.
另: 我这里一直用的是 Java 平台来演示, 但这些 meta 呀, headers 呀, Content-Type 呀, response 呀之类的都是跟平台无关的, 属于 html 规范或 http 协议范畴, 无论你是 php, asp 还是 nodejs 等等, 与这些相关的东西都是类似的, 原理也是相通的. 如果你不是 Java 平台, 应该也不难构建类似的测试.
关于通过响应头下的 Content-Type 条目中的 charset 信息来确定文档的编码就介绍到这里, 下一篇将讨论 BOM 存在时的页面编码的确定问题.