
这一篇将介绍 BOM 在 html 页面编码中的运用. 在最前面曾提到, 它的优先级实际上是最高的, 在这里, 将具体介绍什么是 BOM, 还会解析为什么它的优先级最高, 然后还会构建一些具体的测试来验证这一点.
什么是 BOM?
关于什么是 BOM, 在这篇文章中有详细的介绍:
这里也稍微啰嗦几句, 内容也基本出自上述文章: BOM=Byte Order Mark, 翻译过来就是"字节顺序标识".
具体则分为两种: 小端序(Little endian) 和 大端序(Big endian).
我们知道, 在记事本中 "另存为" 时可以选择编码, 有以下几种:
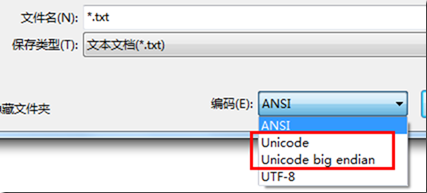
这里的 Unicode 实际就是 UTF-16(小端序).
注: Java 平台中 UTF-16 缺省为 大端序, 与 Windows 恰好相反.
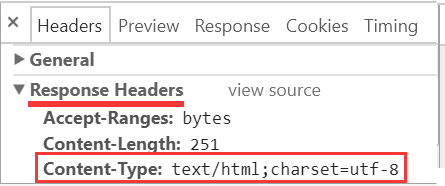
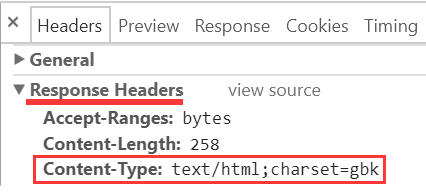
另: 记事本的 UTF-8 默认是带 BOM 的, 而多数 IDE 的编辑器 UTF-8 默认不带 BOM.
{kind=link}