
在前面的网页中的编码与乱码系列中(一, 二, 三, 四, 五 ), 曾多次提到使用 servlet 方式构建的动态响应流, 不过在那里都是直接使用字节流的方式, 不过, 更为常见的方式是使用字符流. 而在前面, 又谈到了 Java 字节流与字符流的话题(一, 二, 三, 四 ).
有了前面的基础, 现在来说下 Java servlet 中使用字符流, 也即是 PrintWriter 时的编码与乱码问题.
回顾字节流的情形
先回顾一下, 在之前的字节流响应中, 我们使用 String.getBytes 方法, 然后总是显式传入编码的参数, 使它与 meta 中或者 header 的声明一致. 比如这样:
// 一致使用 gbk
String meta = "<head><meta charset=\"gbk\"></head>";
os.write((meta + "编码与 meta 一致,GBK.").getBytes("gbk"));
// 一致使用 utf-8
String meta = "<head><meta charset=\"utf-8\"></head>";
os.write((meta + "编码与 meta 一致,UTF-8.").getBytes("utf-8"));
或者这样:
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/rightHeader/utf8")
public class EncodingRightHeaderUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setHeader("Content-type", "text/html;charset=utf-8");
ServletOutputStream os = response.getOutputStream();
os.write("编码与 header 一致,UTF-8.".getBytes("utf-8"));
}
}
只要保持了一致, 就不用担心发生乱码的问题.
使用 PrintWriter 字符流, 缺省编码
现在假如使用 PrintWriter 来作为响应呢? 比如这样:
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.Charset;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet("/encoding/page/printwriter/default")
public class EncodingPrintWriterDefault extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter pw = response.getWriter();
String header = "<html><head><meta charset='utf-8'></head><body>";
String footer = "</body></html>";
String dc = Charset.defaultCharset().toString();
pw.write(header + "default: 缺省字符流" + dc + footer);
}
}
代码中并没有显式传入什么编码的参数, 不像 String.getBytes 那样. 另一方面, 我们知道, 字符流最终还是要转换成字节流, 可是它到底使用了什么编码呢? 是不是 Charset.defaultCharset 中的值呢?
就以上述代码为例, 假如现在在浏览器中查看, 会发现结果是这样的:
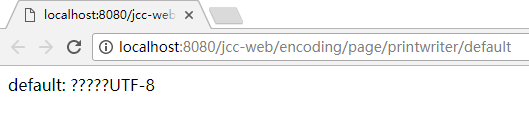
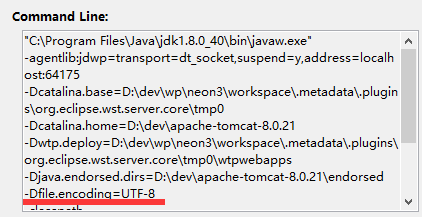
可见 defaultCharset 缺省是 utf-8, 前面说过, 这其实来自于启动 tomcat server 时所传入的参数 –Dfile.encoding, (见前面篇章 Java 字节流与字符流(3) ):
但汉字却没有正确输出, 可见 PrintWriter 并没有采用这个缺省值. 查看 header 中的响应:
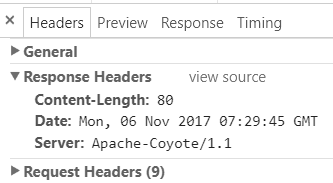
也没有任何编码的指示.
虽然 meta 中声明是 utf-8, 输出的缺省字符集的值也是 utf-8, 可是从最终结果不难看出 PrintWriter 并没有采纳这个值来转换字节流. (实际上它根本不会试图去理解这个).
看一看它的文档说明, 会发现情况有点不一样:

原来没有指定时, PrintWriter 不是用 Charset.defaultCharset 中的值, 而是用 response.getCharacterEncoding 方法中所返回的值, 而没有指定的话, 那个方法其实就返回一个缺省值: ISO-8859-1.
再看看 getCharacterEncoding 方法:
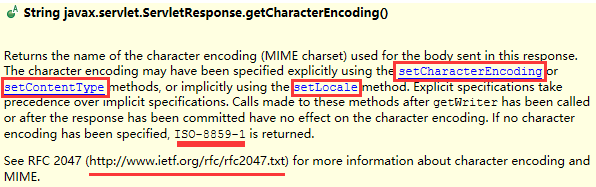
可以看到它的值又是来源于显式的 response.setCharacterEncoding 或 response.setContentType 方法, 或者是隐式的 setLocale 方法. (显式的具有更高的优先级)假如没有, 就用缺省的 ISO-8859-1.
它还提到 RFC 2047 标准, 打开看看, 是关于 MIME 中非 ASCII 文本的消息头扩展(MIME (Multipurpose Internet Mail Extensions) Part Three: Message Header Extensions for Non-ASCII Text)的. 文中有一处提到如果字符集编码缺失, 推荐用 iso8859 系列:

注意这里没有明说是 iso-8859-1, 它说的是 iso-8859-*, 不过 servlet 最终采用的是 iso-8859-1.
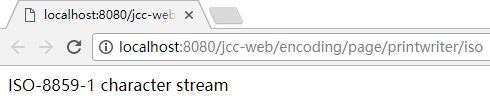
所以现在清楚了, 缺省用 iso-8859-1, 可以用 getCharacterEncoding 得到它的值, 不过 iso-8859-1 不支持中文字符, 所以响应流中不能出现中文:
@WebServlet("/encoding/page/printwriter/iso")
public class EncodingPrintWriterISO extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter pw = response.getWriter();
String header = "<html><head><meta charset='iso-8859-1'></head><body>";
String footer = "</body></html>";
String dc = response.getCharacterEncoding();
pw.write(header + dc + " character stream" + footer);
}
}
结果是这样:
使用 PrintWriter 字符流, 显式指定编码
按照前面说的, 可以在 write 之前使用 setCharacterEncoding 等方法指定编码:
@WebServlet("/encoding/page/printwriter/utf8")
public class EncodingPrintWriterUTF8 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("utf-8");
PrintWriter pw = response.getWriter();
String header = "<html><head><meta charset='utf-8'></head><body>";
String footer = "</body></html>";
pw.write(header + "utf-8 字符流" + footer);
}
}
这样就 OK 了:

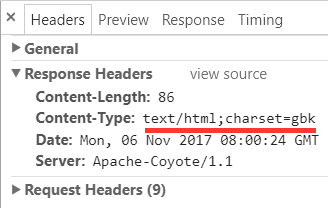
要注意, 这种情况下, response header 中仍然没有 charset 信息, 所以要在 meta 中指定.
也可以用 setContentType (或前面一直用的 setHeader, 其实两者是等价的):
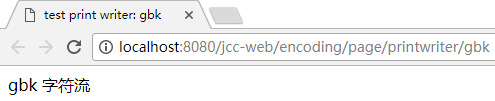
@WebServlet("/encoding/page/printwriter/gbk")
public class EncodingPrintWriterGBK extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html;charset=gbk");
// response.setHeader("Content-type", "text/html;charset=gbk");
PrintWriter pw = response.getWriter();
String header = "<html><head><title>test print writer: gbk</title></head><body>";
String footer = "</body></html>";
pw.write(header + "gbk 字符流" + footer);
}
}
也能达成同样效果:
这种情况下, response header 中包含 charset 信息, 所以前面的代码中可以省略在 meta 中的声明:
那么, 现在我们明白了, PrintWriter 的缺省与普通字符流的缺省是不同的, 机制有所差别.
使用普通字符流, 缺省编码
当然如果你一定要用普通字符流, 也是可以的, 但最后需要主动 flush:
@WebServlet("/encoding/page/normalwriter/default")
public class EncodingNormalWriterDefault extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String dc = Charset.defaultCharset().toString();
Writer osw = new OutputStreamWriter(response.getOutputStream());
String header = "<html><head><meta charset='" + dc + "'></head><body>";
String footer = "</body></html>";
osw.write(header + "使用普通字符流," + dc + footer);
osw.flush();
}
}
这时的缺省就是 Charset.defaultCharset 中的值了, 这里把它拼在了 meta 和最终的输出中, 响应也是正常的:

结果是 utf-8. 跟前面所说的 tomcat server 启动时参数的值一致.
使用普通字符流, 显式指定编码
如果不打算用缺省, 那就直接指定:
@WebServlet("/encoding/page/normalwriter/gbk")
public class EncodingNormalWriterGBK extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
Writer osw = new OutputStreamWriter(response.getOutputStream(), "gbk");
String header = "<html><head><meta charset='gbk'></head><body>";
String footer = "</body></html>";
osw.write(header + "使用普通字符流,GBK" + footer);
osw.flush();
}
}
结果同样是 OK 的:

当然, 一般还是建议使用 PrintWriter 来输出, 而即便你一定要用普通字符流, 也最好不要用缺省.
那么关于 Java servlet 中使用 PrintWriter 时的编码与乱码问题就介绍到这里. 本文中的示例代码见: https://gitee.com/goldenshaw/java_code_complete/tree/0c0993f6ce8972d28e612a18a40d4474772fd884/jcc-web/src/main/java/org/jcc/servlet/encoding/page/writer