
在说完了网页中的编码与乱码(一, 二, 三, 四, 五 ), servlet 中的编码问题 后, 这次来探讨一下 JSP 中的编码与乱码问题.
在之前, 曾谈到过 JSP 与 HTML 间的关系, JSP 本质上是一个 HTML 的模板, 用于在服务端动态生成 HTML, 这点跟 servlet 是类似.
其实 JSP 本质就是 servlet, 一个 JSP 页面它会被编译成一个 java 文件, 实际上就是一个 servlet 类(或其子类, 在文章的后面会具体讨论这个问题).
深入介绍了 JSP 中的编码与乱码问题, 分析对比了 page 指令中的 pageEncoding 属性和 contentType 属性, 还对 JSP 与 servlet 及 HTML 的关系作了一个简要介绍.
在说完了网页中的编码与乱码(一, 二, 三, 四, 五 ), servlet 中的编码问题 后, 这次来探讨一下 JSP 中的编码与乱码问题.
在之前, 曾谈到过 JSP 与 HTML 间的关系, JSP 本质上是一个 HTML 的模板, 用于在服务端动态生成 HTML, 这点跟 servlet 是类似.
其实 JSP 本质就是 servlet, 一个 JSP 页面它会被编译成一个 java 文件, 实际上就是一个 servlet 类(或其子类, 在文章的后面会具体讨论这个问题).
介绍了 Java servlet 使用 PrintWriter 时的编码与乱码问题, 并探讨了 PrintWriter 的缺省编码与普通字符流的缺省编码的差异.
在前面的网页中的编码与乱码系列中(一, 二, 三, 四, 五 ), 曾多次提到使用 servlet 方式构建的动态响应流, 不过在那里都是直接使用字节流的方式, 不过, 更为常见的方式是使用字符流. 而在前面, 又谈到了 Java 字节流与字符流的话题(一, 二, 三, 四 ).
有了前面的基础, 现在来说下 Java servlet 中使用字符流, 也即是 PrintWriter 时的编码与乱码问题.
先回顾一下, 在之前的字节流响应中, 我们使用 String.getBytes 方法, 然后总是显式传入编码的参数, 使它与 meta 中或者 header 的声明一致. 比如这样:
在上一篇中比较了使用字节流和字符流来读取(写入)文本文件的优劣后, 这一篇主要探讨缺省编码这个主题.
通过前面的例子, 已经得出了一个结论: 字符流=字节流+编码.
可以在构建字符流时显示传入编码参数, 那么所得到的字符流就会以该编码来**编码(encode)或解码(decode)**字节流, 这会给文本数据处理带来极大方便.
但有时, 构建字符流时也可以不传入编码参数, 比如如下直接构建一个 InputStreamReader :
深入探讨了缺省情况下浏览器的响应行为, 包括静态和动态的响应, 最后, 对所有情况作了一个简单总结.
在上一篇我们谈论了 BOM 编码的页面, 并知道了它是有最高优先级的. 而这一篇将讨论最后的一个主题, 也就是缺省的情况. 既然名为缺省, 也就不难想到, 它的优先级是最低的, 也即是在其它情况下都无法确定编码时, 才轮到它上场.
前面说到, 缺省就是没有 BOM, 响应头中的 Content-Type 也没有 charset 声明, 文档内也没有 meta charset 的声明, 这时浏览器该如何确定 html 页面的编码呢? 这里将设计一系列实验以探究这个问题.
首先是构建一个缺省的响应. 比如去构建一个 gbk 编码的文档, 自然就没有所谓的 BOM 了;然后用 gbk 编码保存这个文档, 但在文档内也不声明;之后配置服务器的响应头也不带 charset 信息. 这样一来, 浏览器收到这个文档流时无法获得任何有效的编码信息, 就将进入缺省的处理模式.
构建一个缺省的 gbk 文档时有几点要注意. 这点在前面的"文档内编码声明"章节也已经提到过, 特别是你在一个工程缺省编码为 UTF-8 的项目内创建这样的文档时更要注意, 当你删掉 meta charset="gbk" 的声明时, 智能的 IDE 编辑器可能会悄悄调整所使用的编码.
最好是在外部用记事本或 notepad++ 这样的通用文本编辑器来创建一个缺省的 gbk 编码的文档.
深入介绍了 html 页面使用 BOM 编码的情况, 它的优先级为什么最高以及具体的静态页面和动态响应的测试示例.
这一篇将介绍 BOM 在 html 页面编码中的运用. 在最前面曾提到, 它的优先级实际上是最高的, 在这里, 将具体介绍什么是 BOM, 还会解析为什么它的优先级最高, 然后还会构建一些具体的测试来验证这一点.
关于什么是 BOM, 在这篇文章中有详细的介绍:
这里也稍微啰嗦几句, 内容也基本出自上述文章: BOM=Byte Order Mark, 翻译过来就是"字节顺序标识".
具体则分为两种: 小端序(Little endian) 和 大端序(Big endian).
我们知道, 在记事本中 "另存为" 时可以选择编码, 有以下几种:
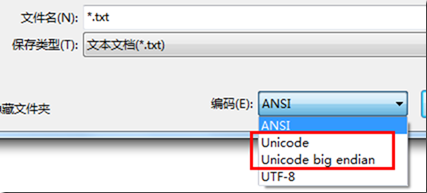
这里的 Unicode 实际就是 UTF-16(小端序).
注: Java 平台中 UTF-16 缺省为 大端序, 与 Windows 恰好相反.
另: 记事本的 UTF-8 默认是带 BOM 的, 而多数 IDE 的编辑器 UTF-8 默认不带 BOM.